
Recently, a client of ours shared with us their frustration that their website’s internal site search results didn’t display the most relevant items when searching for certain keywords. They had done their homework and provided us with a list of over 150 keywords and the expected corresponding search result performance. Their site was built with Drupal 7 and relied on Search API & Search API Solr for content indexing and content display.
Language Processing
Since the website was in Dutch, we started by applying our usual best practices for word matching. No instance of Apache Solr search will work properly if the word matching and language understanding haven’t been appropriately configured. (see also this blog post)
For this particular website, many of the best practices for Apache Solr Search hadn’t been followed. For example, you always need to make sure to store the rendered output of your content and additional data (such as meta tags) in one single field in the index. This way, it’s a lot easier to search all the relevant data. It will make your optimizations easier further down the road and it will render your queries a lot smaller & faster. Also make sure to filter out any remaining HTML code, as it does not belong in the index. Last but not least, make sure to index this data using as little markup as possible, and get rid of the field labels. You can do this by assigning a specific view mode to each content type. If you’re having trouble with these basics, just get in touch with us so we can give you a hand.
Boosting
Once this has been fixed, you can use the boosting functionality in Apache Solr to prioritize certain hypotheses on how much more important a certain factor will be in the overall generation of results. The client website that I mentioned earlier, for example, had some custom code written into it to boost the content based on the content type during the time of indexing.
Apache Solr works with relevance scores to determine where a result should be positioned in relation to all of the other results. Let’s dig into this a bit deeper.
http://localhost:8983/solr/drupal7/select?
q=ereloonsupplement& // Our term that we are searching for
defType=edismax& // The eDisMax query parser is designed to process simple phrases (without complex syntax) entered by users and to search for individual terms across several fields using different weighting (boosts) based on the significance of each field while supporting the full Lucene syntax.
qf=tm_search_api_aggregation_1^1.0& // Search on an aggregated Search Api field containing all content of a node.
qf=tm_node$title^4.0& // Search on a node title
qf=tm_taxonomy_term$name^4.0& // Search on a term title
fl=id,score& // Return the id & score field
fq=index_id:drupal7_index_terms& // Exclude documents not containing this value
fq=hash:e3lda9& // Exclude documents not containing this value
rows=10& // Return top 10 items
wt=json& // Return it in JSON
debugQuery=true // Show me debugging informationWhen looking at the debugging information, we can see the following:
"e3lda9-drupal7_index_terms-node/10485": "n13.695355 = max of:n 13.695355 = weight(tm_search_api_aggregation_1:ereloonsupplement in 469) [SchemaSimilarity], result of:n 13.695355 = score(doc=469,freq=6.0 = termFreq=6.0n), product of:n 6.926904 = idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:n 10.0 = docFreqn 10702.0 = docCountn 1.9771249 = tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:n 6.0 = termFreq=6.0n 1.2 = parameter k1n 0.75 = parameter bn 248.69698 = avgFieldLengthn 104.0 = fieldLengthn",This information shows that item scores are calculated based on the boosting of the fields that our system has had to search through. We can further refine it by adding other boost queries such as:
bq={!func}recip(rord(ds_changed),1,1000,1000) This kind of boosting has been around in the Drupal codebase for a very long time and it even dates back to Drupal 6. It is possible to boost documents based on the date they were last updated, so that more recent documents will end up with higher scores.
Solved?
Sounds great, right? Not quite for the customer, though!
As the client is usually going back and forth with the development company for small tweaks, every change you make as a developer to the search boosting requires a full check on all the other search terms. This needs to be done to make sure the boosting you are introducing doesn’t impact other search terms. It’s a constant battle – and it’s a frustrating one. Even more so because in the above scenario the result that was displayed at the top wasn’t the one that the client wanted to show up in the first place. In the screenshot you can see that for this particular query, the most relevant result according to the customer is only ranked as number 7. We’ve had earlier instances where the desired result wouldn’t even be in the top 50!
To tackle this, we use an in-house application that allows end users to indicate which search results are ‘Not Relevant’, ‘Somewhat Relevant’, ‘Relevant’ or ‘Highly Relevant’, respectively. The application sends direct queries to Solr and allows the client to select certain documents that are relevant for the query. Dropsolid adjusted this so that it can properly work with Drupal Search API Solr indexes for Drupal 7 and 8.
We’ve used the application from the screenshot to fill in all the preferred search results when it comes down to search terms. In the background, it translates this to a JSON document that lists the document IDs per keyword and their customer relevance score from 0 to 3, with 3 being the most relevant.
This is a very important step in any optimization process, as it defines a baseline for the tests that we are going to perform.
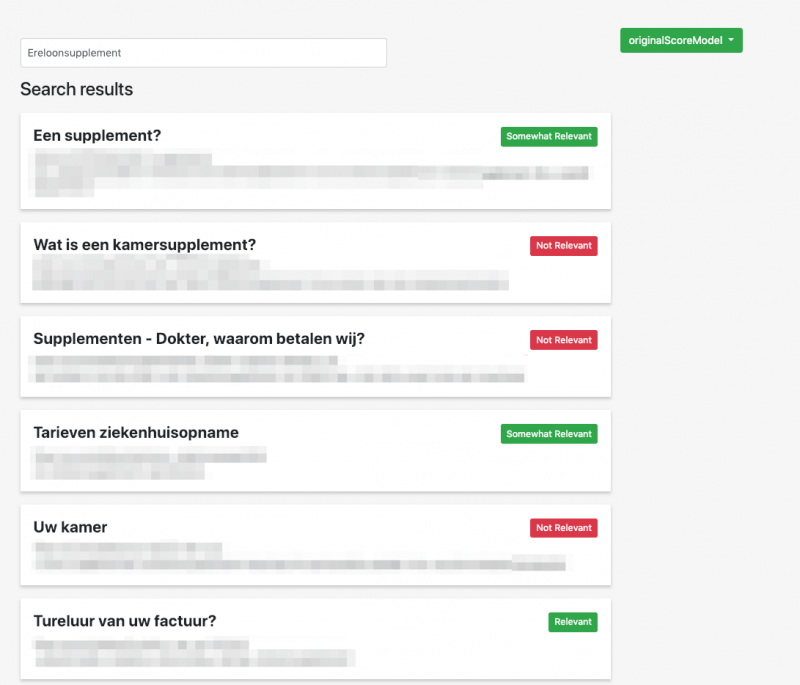
Footnote: This image is a separate application in Python based on a talk of Sambhav Kothari from Bloomberg Tech at Fosdem.
Learning To Rank
We quote from the Apache Solr website: “In information retrieval systems, Learning to Rank is used to re-rank the top N retrieved documents using trained machine learning models. The hope is that such sophisticated models can make more nuanced ranking decisions than standard ranking functions like TF-IDF or BM25.”
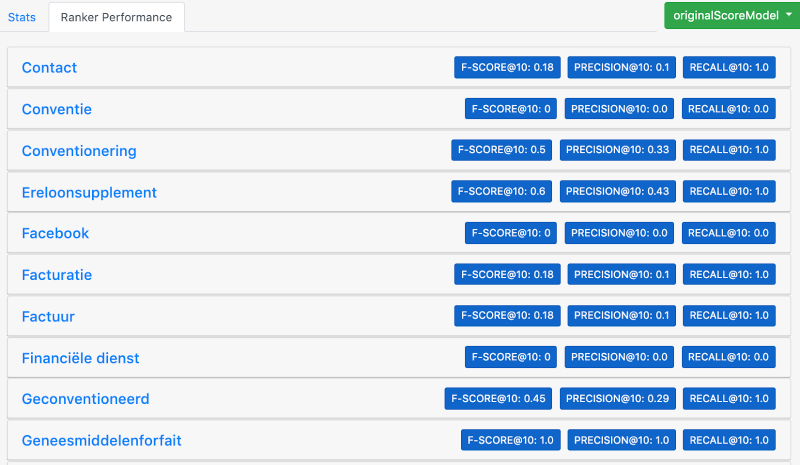
Using the baseline that we’ve set, we can now calculate how well our original boosting impacts the search results. What we can calculate, as shown in the screenshot above, is the F-Score, the recall & precision of the end result when using our standard scoring model.
Precision is the ratio of correctly predicted positive observations to the total predicted positive observations.
The question that Precision answers is the following: of all results that labeled as relevant, how many actually surfaced to the top? High precision relates to the low false positive rate.” The higher, the better, with a maximum of 10.
Src: https://blog.exsilio.com/all/accuracy-precision-recall-f1-score-interpretation-of-performance-measures/
Recall is the ratio of correctly predicted positive observations to the all observations in actual class.
The question recall answers is: Of all the relevant results that came back, what is the ratio compared to all documents that were labeled as relevant? The higher the better, with a maximum of 1.
Src: https://blog.exsilio.com/all/accuracy-precision-recall-f1-score-interpretation-of-performance-measures/
If we just look at the top-5 documents, the combined F-Score is 0.35, with a precision of 0.28 and a recall of 0.61. This is quite bad, as only 60% of our relevant documents appear in the top 5 of all search queries. The precision tells us that from the top-5 documents, only 30% has been selected as relevant.
Training our model
Before all of this can work, we have to let Solr know what possible features exist that it might use to decide the importance of each feature based on feedback. An example of such a feature could be the freshness of a node – based on the changed timestamp in Drupal -, or it could just as well be the score of the query against a specific field or data such as meta tags. For reference, I’ve listed them both below:
{
"name":"freshnessNodeChanged",
"class":"org.apache.solr.ltr.feature.SolrFeature",
"params":{
"q":"{!func}recip( ms(NOW,ds_node$changed), 3.16e-11, 1, 1)"
},
"store":"_DEFAULT_"
},
{
"name":"metatagScore",
"class":"org.apache.solr.ltr.feature.SolrFeature",
"params":{
"q":"{!edismax qf=tm_metatag_description qf=tm_metatag_keywords qf=tm_metatag_title}${query}"
},
"store":"_DEFAULT_"
}Using the RankLib library (https://sourceforge.net/p/lemur/wiki/RankLib/), we can train our model and import it into Apache Solr. There are a couple of different models that you can pick to train – for example Linear or Lambdamart – and you can further refine the model to include the number of trees and metrics to optimize for.
You can find more details at https://lucene.apache.org/solr/guide/7_4/learning-to-rank.html
Applying our model
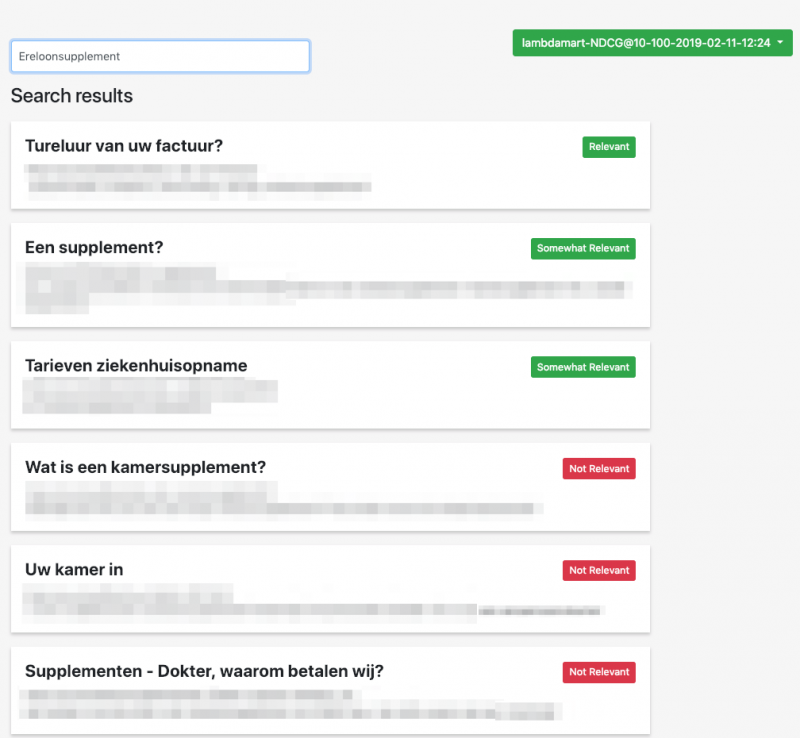
We can, using the rq parameter, apply our newly trained model and re-rank the first 100 results according to the model.
rq={!ltr+efi.query=ereloonsupplement+model=lambdamart-NDCG@10-100-2019-02-11-12:24+reRankDocs=100}If we look at the actual result, it shows us that the search results that we’ve marked as relevant are suddenly surfacing to the top. Our model assessed each property that we defined and it learned from the feedback! Hurray!
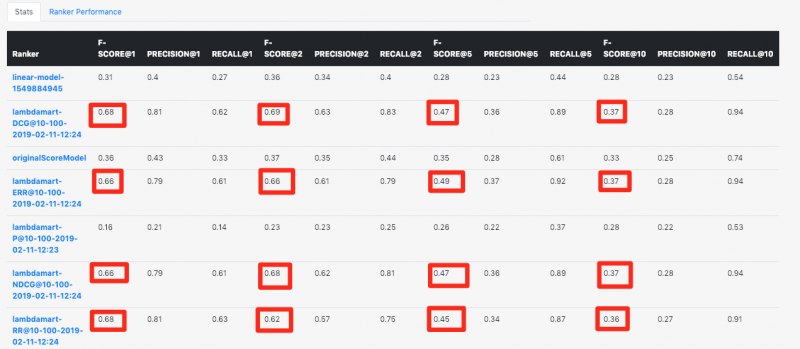
We can also compare all the different models. If we just look at the top-5 documents, the combined F-Score of our best performing model is 0.47 (vs 0.35), with a precision of 0.36 (vs 0.28) and a recall of 0.89 (vs 0.61) This is a lot better, as 90% of our relevant documents appear in the top 5 of all search queries. The precision tells us that from the top-5 documents, 36% has been selected as relevant. This is a bit skewed, though, as for some results we only have one highlighted result.
So, to fully compare, I did the calculations it for the first result. With our original model we only see 46% of our desired results pop up as the first result. With our best-performing model, we improve this score to 79%!
Obviously we still have some work to do to turn 79% up to 100%, but I would like to stress that this result was achieved without changing a single thing to the client’s content. The remaining few cases are missing keywords in the meta tags of Dutch words that somehow are not processed correctly in Solr.
Of course we wouldn’t be Dropsolid if we hadn’t integrated this back into Drupal! Are you looking to give back to the community and needing a hand to optimize your search? Give us the opportunity to contribute this back for you – you won’t regret it.
In brief
We compiled a learning dataset, we trained our model and uploaded the result to Apache Solr. Next, we used this model during our queries to re-rank the last 100 results based on the trained model. It is still important to have a good data model, which means getting all the basics on Search covered first.
Need help with optimizing your Drupal 7 or Drupal 8 site search?